Bu yazımızda makine öğrenmesinde çokça kullanılan Lineer Regresyon ile doğru bulma (eğri uydurma) yöntemini anlatacağız. Bunun için öncelikle lineer regresyon fonksiyonunu tanımlayalım:
$${\mathrm h}_\mathrm\theta(\mathrm x)\;=\;{\mathrm\theta}_0\;+\;{\mathrm\theta}_1\;\mathrm x$$
Bu formülde \(\mathrm h(\mathrm x)\) fonksiyonuna hipotez fonksiyonu denilmektedir. Genel olarak hipotez, ortaya atılan ve daha sonra yapılan deneylerle değiştirilen savlara denir. Makine öğrenmesine uyarlayacak olursak hipotez, verilen girdi değerine karşılık fonksiyonun verdiği cevaptır. Bu cevap, örneklerle (deneyler) birlikte değiştirilir ya da daha doğru tabirle güncellenir. En sonda elde edilen hipotez, genelleştirilmiş olan, örnekleri en iyi temsil eden hipotez olur.
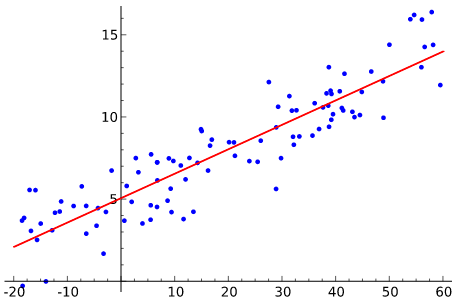 |
| Şekil-1. Hipotez fonksiyonu |
Şekil-1’de X eksenindeki değerler bizim girdi değerlerimiz (mesela öğrencilerin sınavlardaki not ortalaması), Y eksenindekiler (mesela öğrencilerin bir sonraki sınavda aldığı not) de bunlara karşılık gelen değerler olsun. Buradaki amaç, kırmızı ile gösterilen ve girdi değerlerini en iyi temsil eden doğruya ulaşmak. Öğrencilerin belirli bir zamana kadar yapılan sınavlardaki not ortalaması X değerlerini oluşturursa, bir sonraki sınavda alacağı notu da Y değerlerini verecektir. Makine öğrenmesi diliyle anlatırsak, böyle bir durumda X ve Y değerleriyle (eğitim seti) eğitilen fonksiyon, daha önceden görmediği bir girdiye karşılık gelen değeri tahmin edebilir. (Şekil-1 şuradan alınmıştır.)
Basitlik olması için \({\mathrm\theta}_0\;=\;0\) olarak alırsak, fonksiyon orijinden geçen bir doğru fonksiyonuna dönmektedir:
$${\mathrm h}_\mathrm\theta(\mathrm x)\;=\;{\mathrm\theta}_1\;\mathrm x$$
Bu fonksiyonda X değerleri bize verildiğine göre demek ki asıl işimiz \(\mathrm\theta\) parametrelerini bulmak olacaktır(*). Peki böyle bir doğru fonksiyonuna nasıl ulaşacağız, asıl soru bu. Bunun cevabını vermek için cost fonksiyonunu bilmek gerekir. Basitçe Cost fonksiyonu yukarıda bahsettiğimiz hipotezin doğru sonuç verip vermediğini test eder. Bunu da en küçük kareler yöntemini kullanarak, hipotez ile gerçek değer arasındaki mesafeyi ölçerek yapar.
Lineer regresyon için cost fonksiyonunu şöyle hesaplayabiliriz:
$$\mathrm J({\mathrm\theta}_1)\;=\;\frac1{2\mathrm m}\sum_{\mathrm i=0}^\mathrm m(\mathrm h(\mathrm x^{(\mathrm i)})\;-\;\mathrm y^{(\mathrm i)})^2$$
Bu formülle gösterilen fonksiyonda, m eğitim için kullanılan örnek çiftlerin (x,y) sayısını gösterir. Formülde görülen 1/2 katsayısının daha sonra türev alırken işimize yarayacağını göreceğiz.
Yukarıdaki formülde bütün eğitim seti (m) örnekleri için cost fonksiyonunu bulduk. Peki en küçük cost değerini nasıl bulacağız? Bunun için çokça kullanılan ve çeşitli türleri de geliştirilen Gradient Descent adı verilen bir optimizasyon-arama algoritması kullanacağız. Bu algoritma, adı üzerinde (gradient = türev) cost fonksiyonunun kısmi türevi alınarak parametrelerin (\(\mathrm\theta\)) güncellenmesine dayanır. Böylelikle cost fonksiyonu minimuma düşmekte ve örnekleri en iyi temsil eden doğru için Teta parametreleri bulunmaktadır (*:Asıl amaç).
Gradient Descent Algoritmasının çalışması şöyle olur:
En küçük parametre (\(\mathrm\theta\)) değerine ulaşıncaya kadar tekrar et {
$${\mathrm\theta}_1\;:=\;{\mathrm\theta}_1\;-\mathrm\alpha\;\frac{\partial(\mathrm J({\mathrm\theta}_1))}{\partial{\mathrm\theta}_1}$$
}
Yukarıdaki formülde Cost fonksiyonunun \(\mathrm\theta\) parametresine göre kısmi türevi alınırsa parametre güncellemesi aşağıdaki gibi olur:
$${\mathrm\theta}_1\;:=\;{\mathrm\theta}_1\;-\mathrm\alpha\;\frac1{\mathrm m}\sum_{\mathrm i=0}^\mathrm m(\mathrm h(\mathrm x^{(\mathrm i)})\;-\;\mathrm y^{(\mathrm i)})$$
Gradient Descent’in her adımında bütün örneklerin (m) alınmasıyla parametreler yeni değerine güncellenir. Burada “:=” ifadesi matematiksel eşiklik için değil, atama operatörü olarak kullanılır. \(\mathrm\alpha\) değeri öğrenme katsayısı (learning rate) olarak bilinir ve genelde sıfıra yakın değerler seçilir.
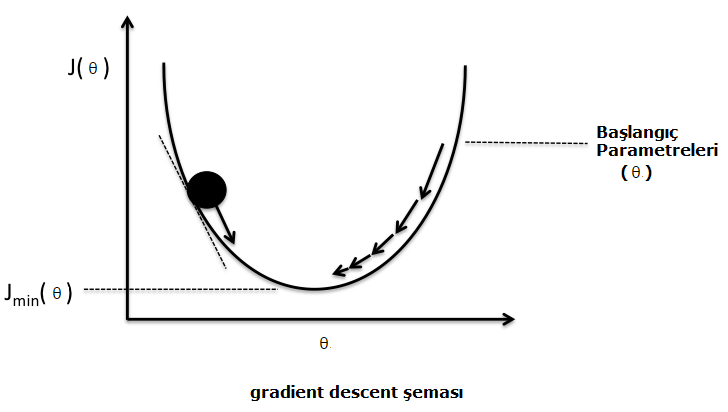 |
| Şekil-2. Gradient Descent şeması |
Temel olarak gradient descent’in yaptığı iş şekil-2’de görülmektedir. Başlangıç parametreleri, \(\mathrm J\) fonksiyonunun o noktadaki \(\mathrm\theta\) değerine göre türevi alınarak güncellenmektedir. (Şekil-2 şu kaynaktan değiştirilmiştir.)
Parametrelerin güncellenmesiyle cost fonksiyonu tekrar hesaplanır ve bu işlem en uygun \(\mathrm\theta\) parametreleri bulununcaya kadar devam eder.
Bir sonraki yazıda tüm bu teorik bilgileri pratiğe dökecek ufak kod parçacıklarıyla devam edeceğiz. Ayrıca türevin nasıl alındığı, türevin yakınsamada nasıl kullanıldığı, öğrenme katsayısının (\(\mathrm\alpha\)) ne olduğu nasıl seçildiği gibi konulara da değineceğiz.
Görüşmek üzere.